1. Intro to Pydra#
Pydra is a lightweight, Python 3.7+ dataflow engine for computational graph construction, manipulation, and distributed execution. Designed as a general-purpose engine to support analytics in any scientific domain; created for Nipype, and helps build reproducible, scalable, reusable, and fully automated, provenance tracked scientific workflows. The power of Pydra lies in ease of workflow creation and execution for complex multiparameter map-reduce operations, and the use of global cache.
Pydra’s key features are:
Consistent API for Task and Workflow
Splitting & combining semantics on Task/Workflow level
Global cache support to reduce recomputation
Support for execution of Tasks in containerized environments
1.1. Pydra computational objects - Tasks#
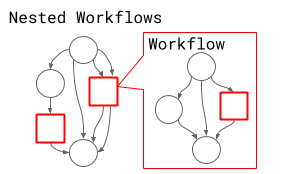
There are two main types of objects in pydra: Task and Workflow, that is also a type of Task, and can be used in a nested workflow.
These are the current Task implemented in Pydra:
Workflow: connects multipleTasks withing a graphFunctionTask: wrapper for Python functionsShellCommandTask: wrapper for shell commandsContainerTask: wrapper for shell commands run within containersDockerTask:ContainerTaskthat uses DockerSingularityTask:ContainerTaskthat uses Singularity
1.2. Pydra Workers#
Pydra supports multiple workers to execute Tasks and Workflows:
ConcurrentFuturesSLURMDaskPSI/J
Before going to next notebooks, let’s check if pydra is properly installed
import pydra