Grouping Task’s Output
In addition to the splitting the input, Pydra supports grouping
or combining the output resulting from the splits.
In order to achieve this for a Task, a user can specify a combiner.
This can be set by calling combine method.
Note, the combiner only makes sense when a splitter is
set first. When combiner=x, all values are combined together within one list,
and each element of the list represents an output of the Task for the specific
value of the input x. Splitting and combining for this example can be written
as follows:
where S represents the splitter, C represents the combiner, \(x\) is the input field, \(out(x_i)\) represents the output of the Task for \(x_i\), and \(out_{comb}\) is the final output after applying the combiner.
In the situation where input has multiple fields and an outer splitter is used, there are various ways of combining the output. Taking as an example the task from the previous section, user might want to combine all the outputs for one specific value of \(x_i\) and all the values of \(y\). In this situation, the combined output would be a two dimensional list, each inner list for each value of \(x\). This can be written as follow:
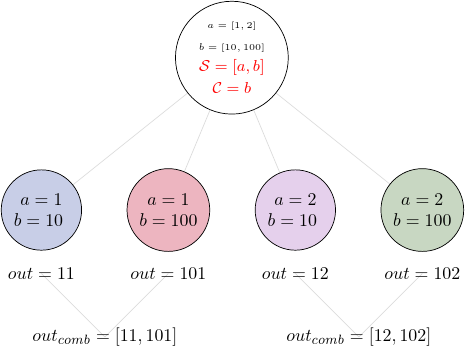
However, for the same task the user might want to combine all values of \(x\) for specific values of \(y\). One may also need to combine all the values together. This can be achieved by providing a list of fields, \([x, y]\) to the combiner. When a full combiner is set, i.e. all the fields from the splitter are also in the combiner, the output is a one dimensional list:
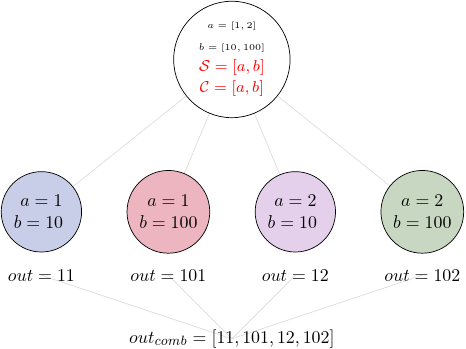
These are the basic examples of the Pydra’s splitter-combiner concept. It is important to note, that Pydra allows for mixing splitters and combiners on various levels of a dataflow. They can be set on a single Task or a Workflow. They can be passed from one Task to following Tasks within the Workflow.